AI in mathematics:
the reliability problem
AI systems infer. In mathematics, however, the same AI can infer different solutions to the same problem*, and even within a single solution, inference can produce correct and incorrect results with the same confidence.
The 100-problem benchmark
We assembled 100 challenging problems of undergraduate mathematics, with emphasis on upper-division and computational topics: multi-step derivations and symbolic or numerical computations, spanning 14 areas:
- Limits & Series
- Differential Calculus
- Numerical Methods
- Integration & Special Integrals
- Multivariable Calculus
- Differential Geometry & Vector Calculus
- Linear Algebra
- ODEs & Special Functions
- Complex Analysis
- Polynomial & Abstract Algebra
- Trigonometry & Fourier Analysis
- Combinatorics & Graph Theory
- Statistics & Probability
- Number Theory
Same AI, same problem, asked six times†
Each of the 100 problems was submitted to each AI system six times in identical form, asking only for the final mathematical answer, not the steps.
One would expect the same system to reproduce the same mathematical answer, since the problem is the same and presented in the same form. Yet repeated submissions produced different answers — not merely in form, but mathematically inequivalent — for a significant number of problems[1].
| AI system | All 6 answers equivalent (%) | Some, but not all, answers different (%) | All 6 answers different (%) |
|---|---|---|---|
| Claude → | 87 | 13 | 0 |
| Codex → | 97 | 3 | 0 |
| DeepSeek → | 43 | 53 | 4 |
| Gemini → | 79 | 20 | 1 |
| Grok → | 93 | 7 | 0 |
| Mistral → | 52 | 41 | 7 |
An equivalent level of disagreements appears when the AI is asked to also show the steps leading to the answer, not just the final result.
Different AIs, same problem
Next we compared the sets of 100 answers of each AI against those of the other AIs. For each problem we grouped the six results by mathematical equivalence: all systems agreeing, one system disagreeing, partial agreement, or no agreement at all.
While people tend to assume that six independent AI systems, each considered state-of-the-art, would converge on the same mathematical result, they often do not[2][3]. And when different AIs return different answers to the same problem, determining which ones, if any, are correct requires a validation process.
| Outcome → | Problems (%) |
|---|---|
| 1 AI disagrees | 27 |
| 2 AIs disagree | 38 |
| 3 AIs disagree (split) | 12 |
| 4 AIs disagree | 2 |
| All 6 AIs disagree | 0 |
| Problems where the AIs did not all agree | 79 |
The six AIs returned mathematically equivalent solutions for only 21% of the problems.
ExaktAI's consensus view: the six engines on one problem, grouped into mathematical-equivalence classes (here, a split).
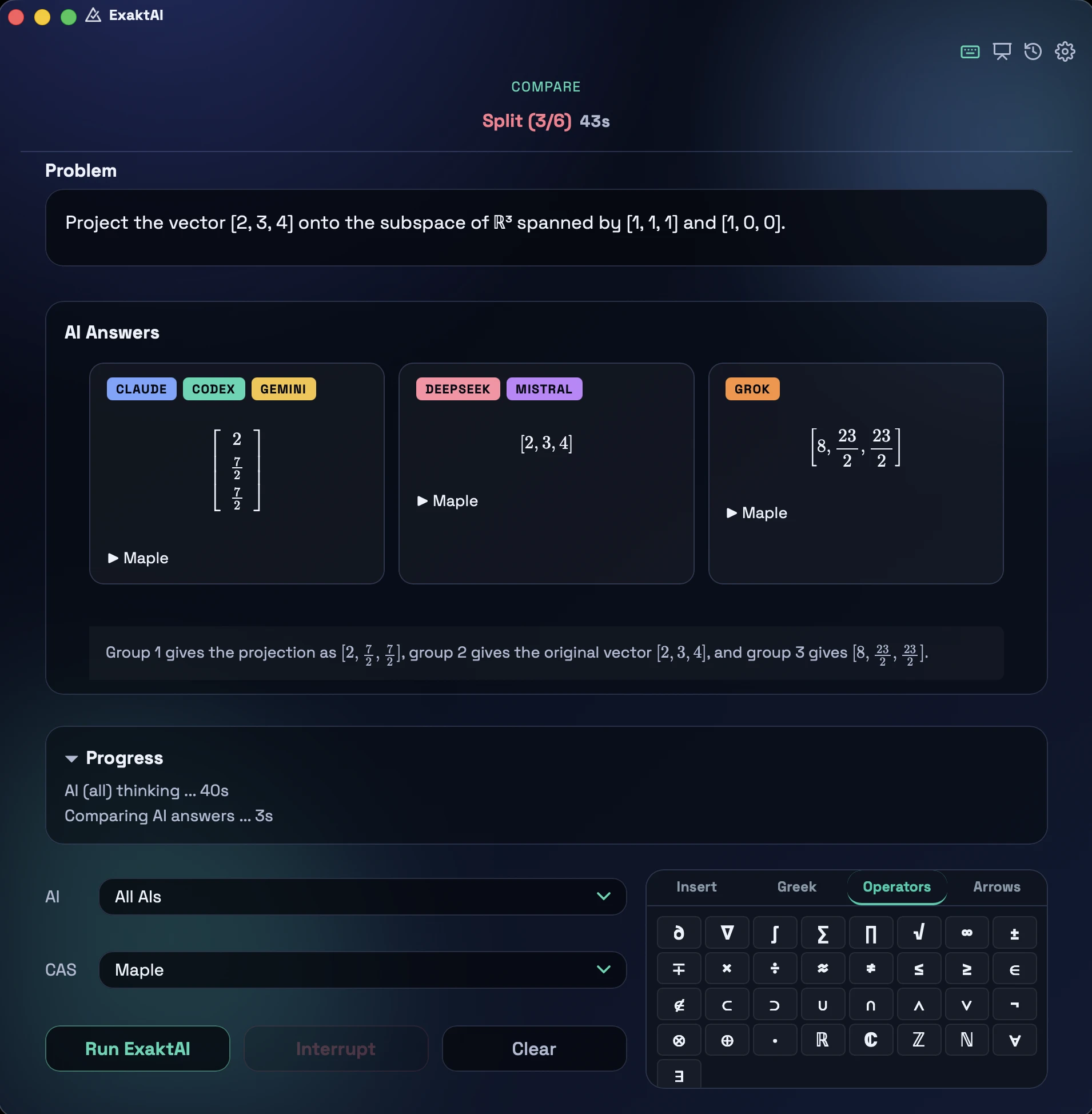
Data and models
All tests run the first week of May 2026. Models used:
| AI system | Model |
|---|---|
| claude (Anthropic) | claude-sonnet-4-6 |
| codex (OpenAI) | gpt-5.3-codex |
| deepseek (DeepSeek) | deepseek-v4-flash |
| gemini (Google) | gemini-2.5-flash |
| grok (xAI) | grok-4-1-fast-reasoning |
| mistral (Mistral AI) | mistral-large-latest |
Related research
- Non-Determinism of “Deterministic” LLM Settings — Atil, Aykent, Chittams et al. (2024). LLM outputs vary run to run even at temperature 0, and the instability shifts model rankings. ↩
- Benchmark Illusion: Disagreement among LLMs and Its Scientific Consequences — Yang & Wang (2026). LLMs at comparable headline accuracy disagree on 16–66% of items; identical scores hide distinct error profiles. ↩
- Cross-Model Disagreement as a Label-Free Correctness Signal — Gorbett & Jana (2026). Operationalizes cross-model disagreement as a reliability signal: when one model is unsure reading another model’s answer, that disagreement predicts wrongness. ↩
* Note on the source of inconsistency: the model generates text through a random process. On problems where the model is confident, runs tend to agree; on harder ones, the randomness surfaces and different runs can arrive at different answers. ↩
† The runs reported on this page were performed during the first week of May 2026, using the model versions listed above. AI systems are actively evolving and outputs vary with constant improvements of the AI models, so the numbers in the tables capture a snapshot of this period, not a durable ranking. ↩